
در قسمت قبل با مرور اصول یادگیری ماشین و انگیزههای استفاده از مدلهای قدرتمندتر، گام بزرگی در جهت درک مدل های زبانی بزرگ برداشتیم، و اکنون با معرفی یادگیری عمیق گام بزرگ دیگری برخواهیم داشت.
در قسمتهای قبل اشاره کردیم که اگر رابطه بین ورودی و خروجی بسیار پیچیده بوده و تعداد متغیرهای ورودی یا خروجی زیاد باشند (و این شرایط در مورد مثالهای تصویری و زبانی که قبلا مطرح کردیم، صدق میکنند)، به مدل های انعطافپذیرتر و قدرتمندتری نیاز داریم. یک مدل خطی یا هر چیزی شبیه به آن، قادر به حل این نوع وظایف طبقه بندی بصری یا احساسی نخواهد بود و اینجاست که شبکههای عصبی وارد میدان میشوند.
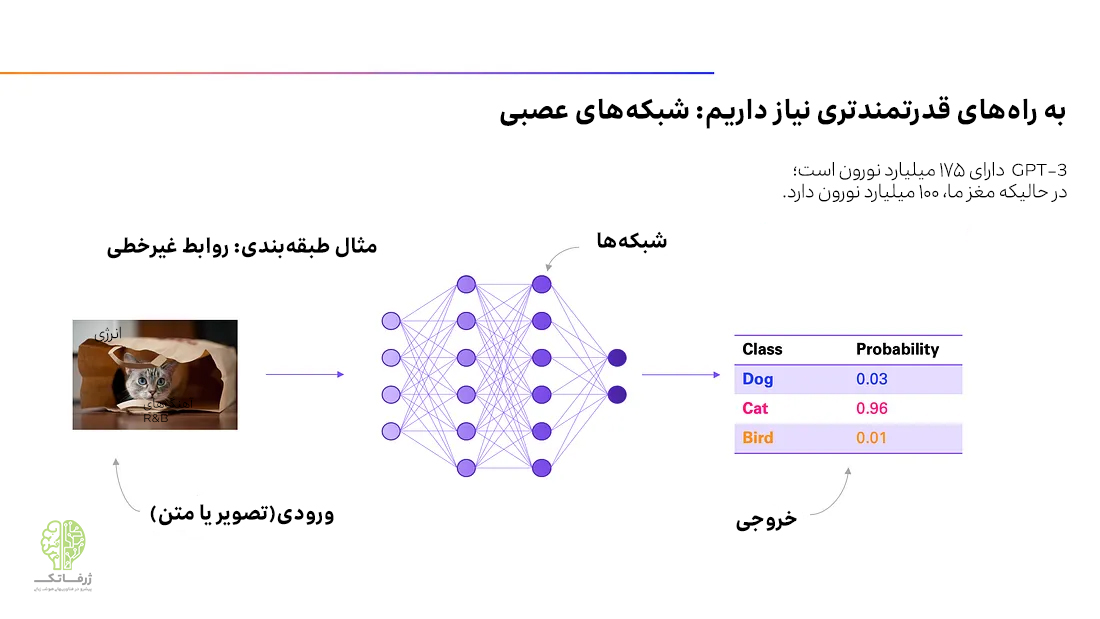
شبکه های عصبی، مدلهای یادگیری ماشین قدرتمندی هستند که مدلسازی روابط پیچیده دلخواه را امکانپذیر میکنند. آنها موتوری هستند که یادگیری چنین روابط پیچیدهای را در مقیاس وسیع امکانپذیر میکنند. در واقع، میتوانیم بگوییم شبکههای عصبی از مغز الهام میگیرند، اگرچه شباهتهای واقعی جای بحث دارند. شبکه های عصبی، معماری بنیادی نسبتا ساده داشته و متشکل از دنبالهای از لایههای نورونی متصل به هم هستند. یک سیگنال ورودی برای پیش بینی نتیجه، از داخل این لایهها عبور می کند. این لایهها را میتوان به صورت لایه های چندگانه رگرسیون خطی در کنار هم در نظر گرفت و سپس با افزودن نوعی غیر خطی بودن به آنها اجازه داد تا روابط غیر خطی را مدل کنند.
شبکههای عصبی اغلب دارای تعداد زیادی لایههای عمیق هستند، به همین دلیل در دسته یادگیری عمیق (Deep Learning) جای میگیرند؛ به این معنی که میتوانند بسیار بزرگ باشند. به عنوان مثال، ChatGPT، یک شبکه عصبی متشکل از ۱۷۶ میلیارد نورون است؛ این در حالی است که مغز انسان، حدود ۱۰۰ میلیارد نورون دارد.
بنابراین، از اینجا به بعد و با درنظر گرفتن این موضوع که نحوه پردازش تصاویر و متن را یاد گرفتهایم؛ شبکه عصبی را به عنوان مدل یادگیری ماشین خود فرض میکنیم. اکنون میتوانیم درباره مدلهای زبانی بزرگ صحبت کنیم و در واقع اینجاست که همه چیز جالب میشود.
بهترین نقطه برای شروع بحث درباره مدل های زبانی بزرگ چیست؟ احتمالاً توضیح اینکه مدل زبانی بزرگ واقعاً به چه معناست. قبلاً فهمیدیم که واژه «بزرگ» به تعداد نورون ها (که پارامترها نیز نامیده میشوند) در شبکه عصبی اشاره دارد. هیچ معیار عدد معینی برای تشخیص بزرگ بودن یک مدل زبانی وجود ندارد، اما شاید بتوان گفت هر چیزی با بیش از یک میلیارد نورون را بزرگ در نظر میگیریم. حالا باید ببینیم منظور از مدل زبانی چیست؟ در ادامه درباره این موضوع بحث میکنیم.

بیایید سوال زیر را به عنوان یک مسئله یادگیری ماشین در نظر بگیریم:
کلمه بعدی در یک دنباله معین از کلمات، به عنوان مثال، در یک جمله یا پاراگراف چیست؟
به عبارت دیگر میخواهیم یاد بگیریم که چگونه کلمه بعدی را پیشبینی کنیم. در بخشهای قبلی، تمام دانش لازم برای یک مسئله یادگیری ماشین را فرا گرفتیم. در واقع، این کار به طبقه بندی احساسات که قبلاً مطرح کردیم، بیشباهت نیست.
در آن مثال، ورودی شبکه عصبی، دنبالهای از کلمات است، اما اکنون هدف، پیش بینی کلمه بعدی است. این کار باز هم، فقط یک نوع طبقه بندی است. تنها تفاوت این است که به جای دو یا چند کلاس، به اندازه تعداد کلمات (مثلا حدود ۵۰ هزار)، کلاس داریم. بنابراین جوهره مدلسازی زبانی را در یک جمله میتوان خلاصه کرد: یادگیری پیش بینی کلمه بعدی. احتمالا متوجه شدهاید که این وظیفه، چند مرتبه بزرگی پیچیدهتر از طبقه بندی احساسات دودویی است. اما اکنون که از شبکههای عصبی و قدرت آنها آگاهیم، جای نگرانی وجود ندارد.
توجه: ما در سراسر این مجموعه مقالات، برای درک بهتر، خیلی از مفاهیم را سادهسازی میکنیم، اما باید توجه کنید که در واقعیت، همه چیز کمی پیچیدهتر است، با این حال، این امر نباید ما را از درک کل ماجرا باز دارد.

اکنون که نوع وظیفهای که باید انجام دهیم را میدانیم، باید به سراغ آموزش شبکه عصبی برویم و برای این کار به داده احتیاج داریم. در واقع ایجاد دادههای زیاد برای وظیفه «پیشبینی کلمه بعدی» دشوار نیست. متون فراوانی در اینترنت، کتابها، مقالات تحقیقاتی و موارد دیگر وجود دارد و ما به راحتی میتوانیم یک مجموعه داده عظیم از همه آنها ایجاد کنیم. حتی نیازی به برچسب زدن دادهها نداریم، زیرا خودِ کلمه بعدی، برچسب است، به همین دلیل به این روش یادگیری خود نظارتی (self-supervised learning) نیز میگویند.
تصویر بالا نحوه انجام این کار را نشان میدهد. فقط میتوان برای آموزش، یک دنباله را به چند دنباله تبدیل کرد. ما تعداد زیادی از چنین دنبالههایی داریم. نکته مهم این است که این کار را برای تعداد زیادی از دنبالههای کوتاه و طولانی (تا هزاران کلمه) انجام دهیم تا در هر زمینهای یاد بگیریم که کلمه بعدی باید چه باشد.
به طور خلاصه، تمام کاری که اینجا انجام میدهیم این است که یک شبکه عصبی (LLM) را آموزش دهیم تا کلمه بعدی را در یک دنباله معین از کلمات پیشبینی کند. مهم نیست که آن دنباله طولانی یا کوتاه، به آلمانی یا انگلیسی یا هر زبان دیگری باشد. حتی مهم نیست یک توییت باشد یا یک فرمول ریاضی، یک شعر یا یک قطعه کد؛ زیرا همه اینها دنباله هایی هستند که در دادههای آموزشی خواهیم یافت.
اگر یک شبکه عصبی به اندازه کافی بزرگ، و همچنین داده های کافی داشته باشیم، LLM در پیش بینی کلمه بعدی واقعاً خوب عمل میکند. آیا بینقض خواهد بود؟ نه، البته که نه، زیرا اغلب اوقات، کلمات متعددی وجود دارند که می توانند کلمه بعدی یک دنباله باشند. با این حال مدل، در انتخاب یکی از کلمات مناسب که از نظر نحوی و معنایی مناسب باشد، خوب عمل میکند.
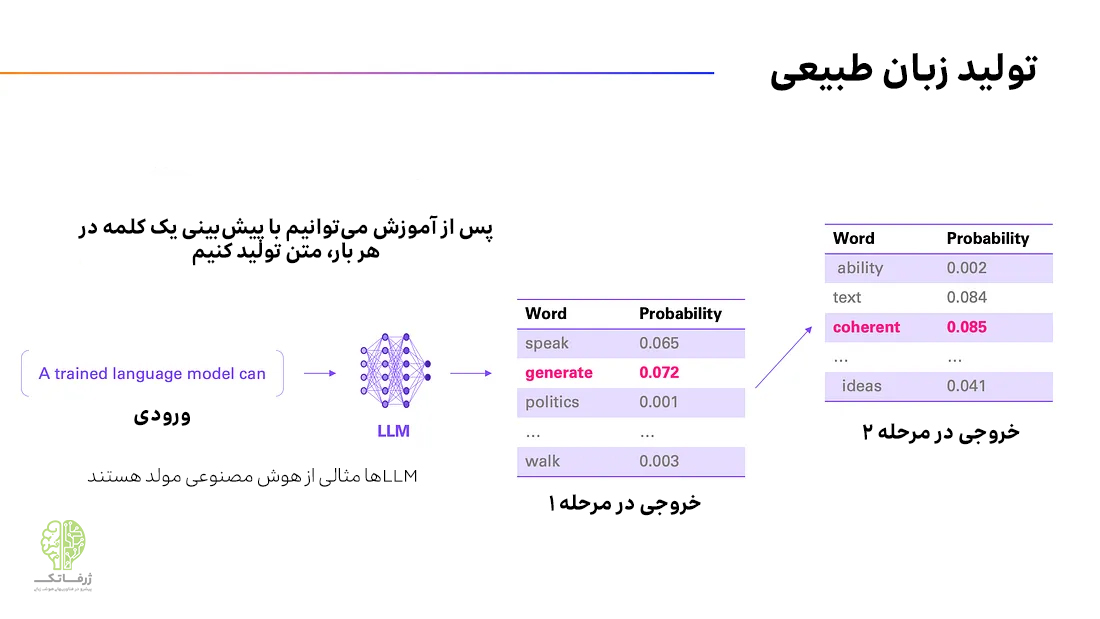
اکنون که میتوانیم یک کلمه را پیشبینی کنیم، میتوانیم این دنباله توسعهیافته را به LLM ورودی بدهیم و کلمه دیگری را پیشبینی کنیم و همینطور الی آخر. به عبارت دیگر، اکنون با استفاده از LLM آموزش دیده خود میتوانیم نه فقط یک کلمه، بلکه متن تولید کنیم. به همین دلیل است که مدل های زبانی بزرگ نمونهای از چیزی هستند که ما آن را هوش مصنوعی مولد (Generative AI) مینامیم. بنابراین به LLM آموختیم که هر بار یک کلمه تولید کند.
نکتهی مهم دیگر آنکه لزوماً همیشه نباید محتملترین کلمه را پیشبینی کنیم؛ در عوض میتوانیم مثلاً از پنج کلمه محتمل در هربار، نمونهبرداری کنیم. این امر میتواند منجر به خلاقیت بیشتر LLM شود. برخی ازLLM ها به شما این امکان را می دهند تا انتخاب کنید که خروجی چقدر قاطعانه یا خلاقانه باشد. به همین دلیل است که وقتی از ChatGPT (که از همین استراتژی نمونهبرداری استفاده میکند) میخواهید که پاسخش را بازتولید کند، پاسخی یکسان با دفعه اول دریافت نمیکنید.
حالا که صحبت از ChatGPT شد، شاید بپرسید چرا نام آن را ChatLLM نگذاشتهاند؟ زیرا مدلسازی زبان، پایان ماجرا نیست، بلکه تازه شروع داستان است! در قسمت بعد فراخواهیم گرفت که GPT در ChatGPT به چه معناست.