
در قسمت قبل از سری مقالات نحوه عملکرد مدل های زبانی بزرگ ، مقدمه کوتاهی درباره هوش مصنوعی و شاخههای آن ارائه کردیم. در این قسمت به سراغ یادگیری ماشین میرویم.
هدف یادگیری ماشین کشف الگو در دادههاست؛ به طور ویژه، الگویی که رابطه بین ورودی و خروجی را توصیف میکند. برای روشن شدن موضوع بهتر است با یک مثال شروع کنیم. فرض کنید میخواهیم دو ژانر موسیقی را از یکدیگر جدا کنیم: رگیتون (reggaeton) و آر اند بی (R&B). رگیتون یک ژانر موسیقی شهری لاتین است که به ریتم تندش شهرت دارد. آر اند بی ژانری است که ریشه در سنت موسیقی آفریقایی-آمریکایی دارد و با آوازهای زیبا و ترکیبی از آهنگهای شاد و آرامتر معروف است.
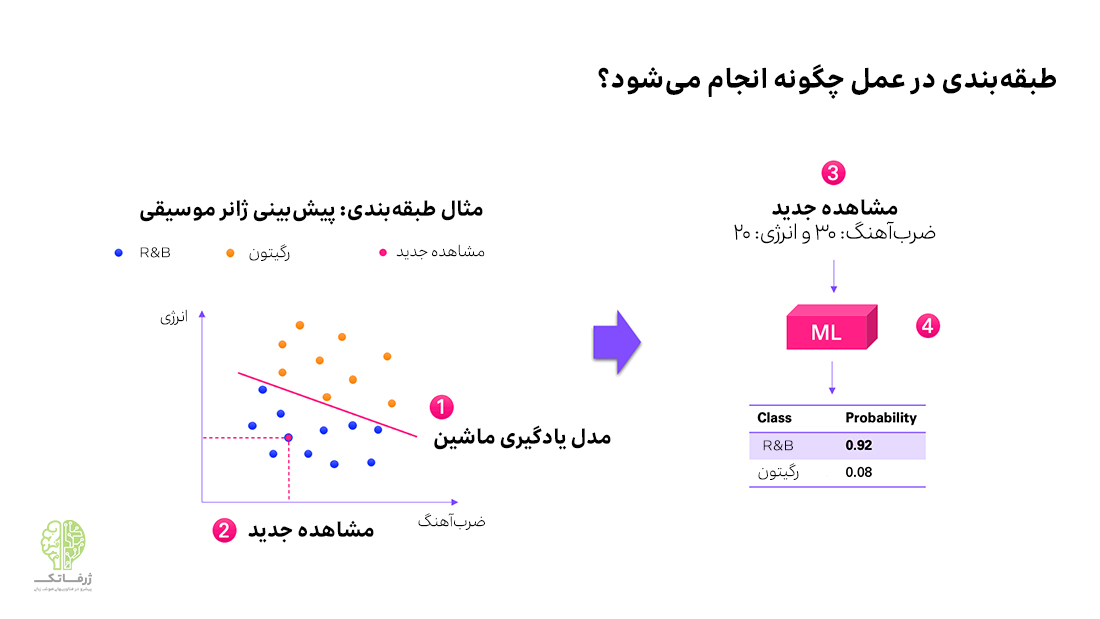
فرض کنید بیست آهنگ داریم و ضرب آهنگ (tempo) و انرژی هر کدام را هم میدانیم. این دو پارامتر برای هر آهنگی به راحتی قابل محاسبه و اندازه گیری هستند. علاوه بر این هر یک از این آهنگها را با توجه به ژانر (reggaeton یا R&B) برچسب گذاری کردهایم. وقتی دادهها را روی نمودار رسم میکنیم، میبینیم که آهنگهای با انرژی و ضربآهنگ بالا عمدتا رگیتون بوده و آهنگهای آرامتر (ضربآهنگ پایین) و کم انرژیتر، در دستهبندی آر اند بی قرار دارند.
با این حال ما نمیخواهیم برچسب گذاری را به صورت دستی (در این مثال گوش دادن به آهنگ و تشخیص ژانر آن) انجام دهیم، چرا که این کار، فرآیندی زمانبر بوده و مقیاسپذیر نیست. در عوض میتوانیم رابطه بین پارامترهای موسیقی (ضرب آهنگ، انرژی) و ژانر را بیاموزیم و پس از آن فقط با استفاده از این دو پارامتر، ژانر آهنگ را پیشبینی کنیم.
در شاخه یادگیری ماشین، به این نوع مسائل، مسائل طبقه بندی (classification) میگوییم؛ زیرا متغیر هدف (ژانر) میتواند فقط یکی از کلاسها یا برچسبهای ثابت (در اینجا رگیتون و آر اند بی) باشد؛ برخلاف یک مسئله رگرسیون که هدف، یک مقدار پیوسته (مثلاً دما یا فاصله) است.
اکنون میتوانیم یک مدل یادگیری ماشین (یا طبقهبندیکننده) را با استفاده از مجموعه دادههای برچسبگذاری شده (که در این مسئله مجموعه آهنگهایی است که ژانر آنها را میدانیم) «آموزش» دهیم. از نظر بصری، کاری که «آموزش دادن مدل» در این مسئله انجام میدهد، معادل پیدا کردن خطی روی نمودار است که به بهترین وجه این دو کلاس را از هم جدا کند.
اما پیدا کردن این خط چه کمکی به ما میکند؟ با پیدا کردن این خط میتوانیم ژانر هر آهنگ جدید را بسته به این که در کدام سمت این خط قرار میگیرد، پیشبینی کنیم. در این روش تنها دادهای که نیاز داریم پارامترهای ضرب آهنگ و انرژی است. این روش بسیار سادهتر و مقیاسپذیرتر از این است که به صورت دستی ژانری را برای هر آهنگ تعیین کنیم.
هرچه از خط دورتر باشیم، میتوانیم در مورد درست بودن پیشبینی مطمئنتر باشیم. بنابراین در اغلب موارد میتوانیم بر اساس فاصله از خط، دربارهی اطمینان از صحت یک پیشبینی اظهار نظر کنیم. برای مثال، برای آهنگ جدیدی که میدانیم کمانرژی و دارای ضرب آهنگ پایین است، میتوانیم با احتمال ۹۸ درصد مطمئن باشیم که یک آهنگ آر اند بی است و با احتمال دو درصد رگیتون است.
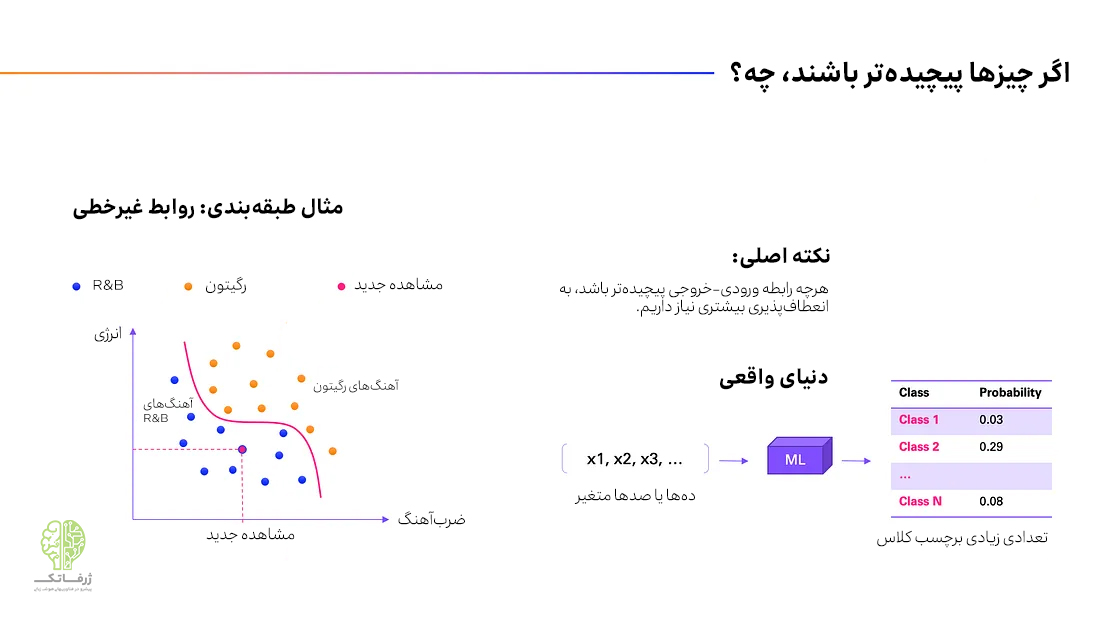
با این حال، مسائل واقعی اغلب پیچیدهتر هستند. در اکثر مسائل واقعی، ممکن است بهترین مرز برای جداسازی کلاسها، یک خط صاف نباشد. رابطهی بین ورودیها و خروجی نیز معمولا بسیار پیچیدهتر است و ممکن است مانند تصویر بالا به صورت منحنی بوده و یا حتی پیچیدهتر از آن باشد.
مسائل دنیای واقعی از جهات دیگری نیز پیچیدهتر هستند. مثلاً برخلاف مثال قبلی، به جای تنها دو ورودی، دهها، صدها یا حتی هزاران پارامتر ورودی داریم. علاوه بر این، اغلب بیش از دو کلاس وجود داشته و همه کلاسها میتوانند از طریق یک رابطه غیرخطی و فوقالعاده پیچیده به همه این ورودیها وابسته باشند. حتی در همین مثال هم میدانیم که در واقعیت بیشتر از دو ژانر موسیقی وجود دارد. همچنین برای تشخیص ژانر به پارامترهای ورودی بسیار بیشتری از دو مورد تمپو و انرژی نیاز است. رابطهی بین این پارامترها نیز یک رابطهی بسیار ساده ی خطی نیست.
نکته کلیدی این است که هر چه رابطه بین ورودی و خروجی پیچیدهتر باشد، برای یادیگیری این رابطه به مدل یادگیری ماشینی پیچیدهتر و قدرتمندتری نیاز داریم. معمولاً با افزایش تعداد ورودی و کلاسها پیچیدگی نیز افزایش مییابد. علاوه بر همهی نکات گفته شده، برای رسیدن به یک دقت پیشبینی مناسب، به دادههای بسیار بیشتری نیز نیاز داریم. در ادامه در مورد این موضوع بیشتر بحث خواهیم کرد.
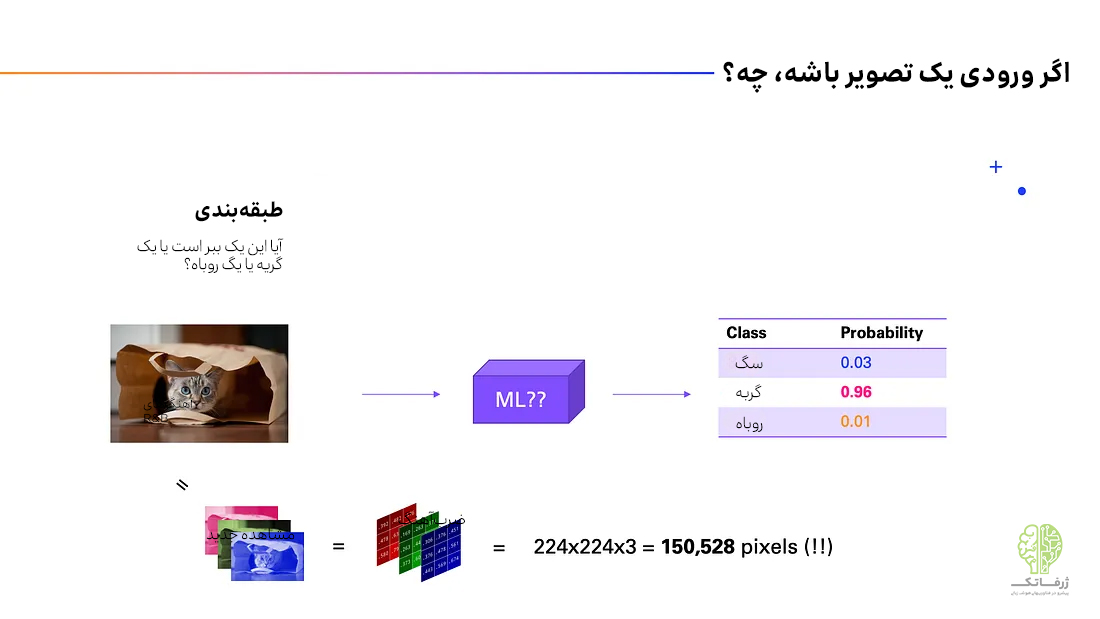
بیایید به سراغ یک مسئلهی متفاوت برویم که ورودی آن، یک تصویر است. سه برچسب احتمالی به عنوان خروجی داریم: ببر، گربه و روباه. فرض کنید هدف این است که از یک گله گوسفند محافظت کنیم و اگر ببر دیدیم آژیر خطر را به صدا درآوریم، اما اگر گربه یا روباه دیدیم آژیر خطر را فعال نکنیم.
میدانیم که این یک مسئله طبقهبندی است چون خروجی فقط میتواند یکی از چند کلاس ثابت باشد. بنابراین، درست مثل قبل میتوانیم از دادههای برچسبدار موجود (یعنی تصاویر با برچسب حیوان مربوطه) استفاده کرده و یک مدل یادگیری ماشین را آموزش دهیم.
حال پرسش این است که یک ورودی تصویری را دقیقا چگونه باید پردازش کنیم، زیرا میدانیم که کامپیوتر فقط میتواند ورودیهای عددی را پردازش کند. پارامترهای ورودی مثال قبلی (انرژی و تمپو) هر دو پارامترهای عددی بودند. خوشبختانه، تصاویر نیز ورودیهای عددی هستند، زیرا هر تصویر از مجموعهای از پیکسلها تشکیل شده است. تصاویر دارای ارتفاع، عرض و سه کانال (قرمز، سبز و آبی) هستند. بنابراین به لحاظ نظری میتوانیم پیکسلها را مستقیما به مدل یادگیری ماشین وارد کنیم.
اما اکنون با دو مشکل روبرو هستیم. اول اینکه، حتی یک تصویر کوچک و با کیفیت پایین ۲۲۴×۲۲۴ از بیش از ۱۵۰ هزار پیکسل تشکیل شده است (۲۲۴x224x3). در مورد اکثر مثالهای یادگیری ماشین میتوان از صدها متغیر ورودی (به ندرت بیشتر از هزار) صحبت کرد، اما اکنون حداقل ۱۵۰,۰۰۰ متغیر داریم.
دوما، رابطه بین پیکسلها و برچسب کلاس، رابطهی بسیار پیچیدهای است. مغز ما این توانایی را دارد که به راحتی ببر، روباه و گربه را از هم تشخیص دهد، با این حال، اگر ۱۵۰,۰۰۰ پیکسل را یکی یکی میدیدیم (مثل شیوهای که مدل، تصویر را میبیند)، هیچ ایدهای از محتوای کلی تصویر نداشتیم. بنابراین پیدا کردن رابطه بین پیکسلهای تصویر با برچسب مربوط به آن برای مدل هم کار بسیار سختی است.
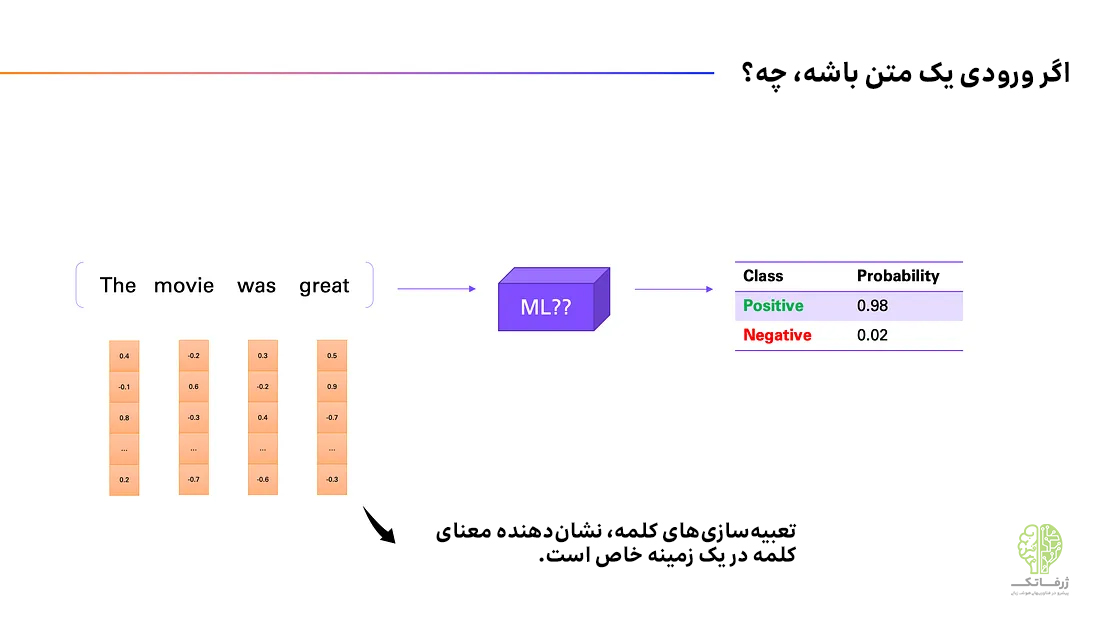
بیایید نوع دیگری از رابطه ورودی-خروجی را در نظر بگیریم که بسیار پیچیده است: رابطهی میان یک جمله و حس مربوط به آن (sentiment). در اینجا منظور از حس، حسی است که یک جمله به خواننده منتقل میکند؛ که میتواند مثبت یا منفی باشد.
پس ورودی ما در این مسئله دنبالهای از کلمات، یعنی یک جمله است و متغیر خروجی نیز حس مربوط به آن جمله است. این مسئله نیز مانند مثالهای قبلی، از نوع طبقهبندی است؛ این بار با دو برچسب ممکنِ مثبت یا منفی. باز هم مانند مثال قبل، ما انسانها این رابطه را به طور طبیعی درک میکنیم، اما آیا میتوانیم به راحتی به یک مدل یادگیری ماشین را آموزش دهیم تا این کار را انجام دهد؟
قبل از پاسخ دادن به این سوال، ابتدا باید مشخص کنیم که چگونه میتوان کلمات را به ورودیهای عددی تبدیل کرد. این مسئله پیچیدهتر از آن چیزی است که در مثال تصویر دیدیم چون همانطور که گفته شد، تصاویر اساساً عددی هستند؛ اما کلمات چنین نیستند.
برای این منظور از تعبیه سازی کلمه (word embedding) استفاده میشود. به طور خلاصه، تعبیه سازی کلمه، بخش معنایی و دستوری کلمه در یک متن خاص را به صورت عددی نمایش میدهد. این تعبیهها را میتوان در فرآیند آموزش مدل اصلی یا از طریق آموزش مدلهای دیگر بدست آورد. معمولاً هر تعبیه سازی کلمه شامل دهها تا هزاران متغیر است.
در مجموع چیزی که باید بدانیم این است که میتوانیم یک جمله را به دنبالهای از ورودیهای عددی تبدیل کرده و سپس از این تعبیه سازیها به عنوان ورودی برای مدل یادگیری ماشین استفاده کنیم. اکنون با چالشهایی مشابه مثال قبلی مواجه هستیم. اول اینکه برای یک جمله طولانی (یا پاراگراف یا حتی کل یک سند)، به دلیل اندازهی بزرگ تعبیه سازی های کلمات، تعداد زیادی ورودی خواهیم داشت.
دومین مشکل، رابطه میان زبان و حس آن است که رابطهی بسیار پیچیدهای است. برای مثال به جملهای مثل این فکر کنید : «در روزی که همه چیز خوب پیش میرفت، ناگهان باران شروع به باریدن کرد». تحلیل احساسی این جمله با استفاده از تعبیه سازی کلمه به کلمه آن، بسیار سخت است؛ زیرا به اشکال متفاوتی میشود آن را تحلیل کرد. این جمله میتواند هم معنی مثبتی داشته باشد و هم منفی و تنها از روی کلمات آن نمیشود به نتیجهی قطعی رسید. برای این مسئله ما به یک مدل یادگیری ماشین فوقالعاده قدرتمند و مقدار زیادی داده نیاز داریم. اینجا جایی است که یادگیری عمیق وارد میدان میشود. مبحث مهمی که در قسمت بعدی به آن خواهیم پرداخت.