
در قسمت قبل درباره یادگیری عمیق صحبت کردیم و پس از آن به طور مستقیم به دنیای مدل های زبانی بزرگ وارد شده و وظیفه «پیشبینی کلمه بعدی» را بررسی کردیم. سپس پا را فراتر گذاشته و داستان هوش مصنوعی مولد را آغاز کردیم و وعده دادیم که در این قسمت درباره مشهورترین هوش مصنوعی مولدِ این روزها یعنی ChatGPT و جزییاتش بیشتر صحبت کنیم. قبل از هر چیز اجازه دهید با نام آن آغاز کنیم: GPT در ChatGPT به چه معناست؟
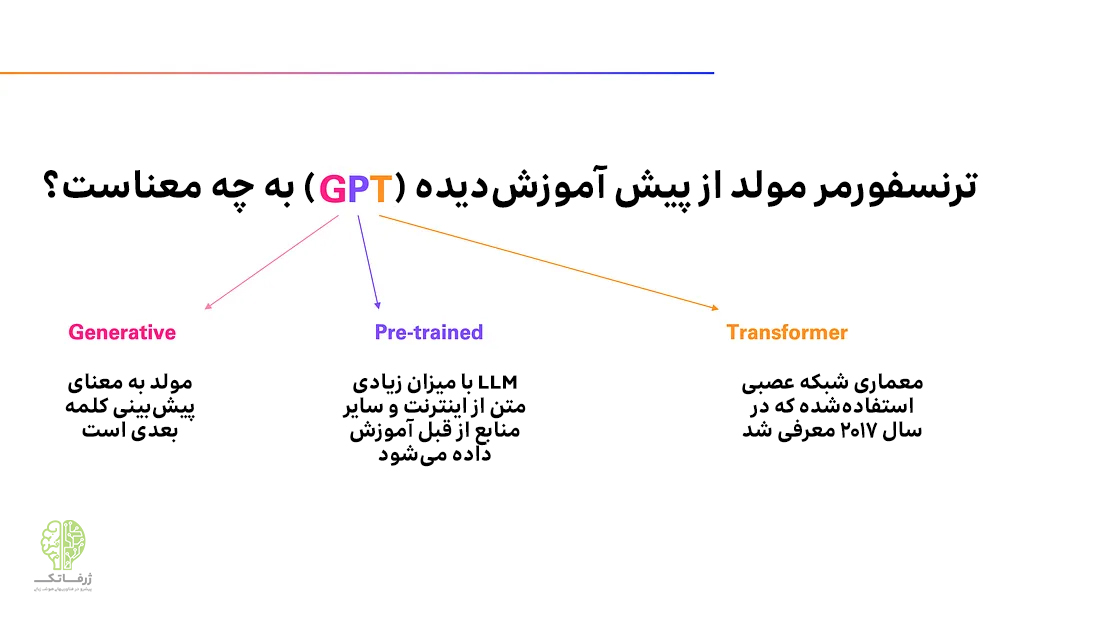
تا الان یاد گرفتیم که G مخفف generative یعنی مولد است؛ به این معنا که برای تولید زبان آموزش داده شده است. اما P و T مخفف چه چیزهایی هستند؟
حرف T مخفف transformer به معنی مبدل است و نوع معماری شبکه عصبی استفاده شده را نشان میدهد. نقطه قوت اصلی معماری ترنسفورمر، این است که بسیار خوب کار میکند، زیرا میتواند توجه خود را بر روی بخشهایی از دنباله ورودی متمرکز کند که مرتبطترین بخشها هستند. میتوانید بگویید که این کار شبیه به کاری است که انسان انجام میدهد؛ زیرا ما نیز باید توجه خود را بر آنچه از همه مرتبطتر است متمرکز کنیم و بقیه را نادیده بگیریم.
حال به P که مخفف pre-training به معنای پیشآموزش است، میپردازیم. در ادامه خواهیم گفت که چرا ناگهان شروع به صحبت در مورد پیش آموزش و نه فقط آموزش میکنیم. دلیل آن این است که مدل های زبانی بزرگ مانند ChatGPT در واقع در چند مرحله آموزش داده میشوند.

پیشآموزش در هوش مصنوعی مولد
مرحله اول پیشآموزش است و دقیقاً همان چیزی است که ما در حال حاضر پشت سر گذاشتهایم. این مرحله به حجم عظیمی از دادهها برای یادگیری پیشبینی کلمه بعدی نیاز دارد. در این مرحله، مدل نه تنها تسلط بر گرامر و نحو زبان را میآموزد، بلکه دانش زیادی در مورد جهان و حتی برخی تواناییهای نوظهور دیگر که بعداً در مورد آنها صحبت خواهیم کرد را بهدست میآورد.
حالا چند سؤال پیش میآید: اولاً، مشکل این نوع پیشآموزش چیست؟ مطمئناً چند مشکل وجود دارد، اما مشکلی که در اینجا میخواهیم به آن اشاره کنیم مربوط به مواردی است که LLM واقعاً آموخته است. به این معنا مدل زبانی بزرگ، عمدتاً یاد گرفته که تنها حول یک موضوع چرخ بزند و ممکن است این کار فوقالعاده خوب انجام دهد. با این حال ممکن است به ورودیهایی دیگری که معمولاً به یک هوش مصنوعی میدهید، مانند یک سؤال یا یک دستورالعمل، به خوبی پاسخ نمیدهد. مشکل این است که این مدل یاد نگرفته است که دستیار باشد و به همین دلیل رفتار یک دستیار را ندارد.
به عنوان مثال، اگر از یک LLM در مرحله پیشآموزش بپرسید: «نام شما چیست؟» ممکن است پاسخ دهد «نام خانوادگی شما چیست؟». صرفاً به این دلیل که در طول پیشآموزش، چنین نوع دادههایی را دیده است. بنابراین فقط سعی میکند دنباله ورودی را کامل کند. یا صرفاً به این دلیل که این نوع ساختار زبانی، یعنی دستورالعملی که یک پاسخ به دنبال آن میآید، معمولاً در دادههای آموزشی دیده نمیشود؛ مثل وبسایتهای مشهور Quora یا StackOverflow.
پس در این مرحله، پاسخهای LLM با خواستههای انسان همسو نیست. همسو بودن، یک لازمهی مهم برای LLM است. در ادامه یاد خواهیم گرفت که چگونه این مشکل را تا حد زیادی برطرف کنیم، زیرا همانطور که مشخص است، LLM های از پیش آموزشدیده، کاملاً قابل هدایت هستند. بنابراین حتی اگر در ابتدا به دستورالعملها پاسخ خوبی ندهند، میتوان به آنها آموزش داد که این کار را انجام دهند.
تنظیم دقیق دستورالعمل و RLHF در هوش مصنوعی مولد
اینجاست که تنظیم دستورالعمل وارد میشود: LLM از قبل آموزشدیده را با تواناییهای فعلیاش برمیداریم و اساساً همان کاری را انجام میدهیم که قبلاً انجام میدادیم – یعنی یاد دادن پیشبینی یک کلمه در هر بار؛ اما اکنون این کار را فقط با استفاده از آموزش باکیفیت و جفت دستورالعمل- پاسخ به عنوان داده های آموزشی انجام میدهیم.
به این ترتیب، مدل فراموش میکند که صرفاً یک تکمیلکننده متن باشد و یاد میگیرد که به یک دستیار مفید تبدیل شود که دستورالعملها را دنبال کرده و پاسخی مطابق با اهداف کاربر ارائه دهد. اندازه مجموعه داده دستورالعمل معمولاً بسیار کوچکتر از مجموعه پیشآموزش است؛ به این دلیل که ساخت جفتهای دستورالعمل-پاسخ با کیفیت بالا، بسیار گرانتر بوده و معمولاً توسط انسان تهیه میشوند؛ و با برچسبهای ارزان قیمتی که در پیشآموزش استفاده میکردیم، تفاوت زیادی دارند. به همین دلیل است که این مرحله تنظیم دقیق دستورالعمل نظارت شده (supervised instruction fine-tuning) نیز نامیده میشود.
همچنین مرحله سومی به نام یادگیری تقویتی از بازخورد انسانی (RLHF) وجود دارد که برخی از LLMها مانند ChatGPT آن را پشت سر میگذارند. ما در اینجا به جزئیات این مرحله نخواهیم پرداخت، اما اینجا هم هدف، مشابه مرحله تنظیم دقیق دستورالعمل است. RLHF همچنین به همسویی پاسخ با اهداف انسانی کمک کرده و تضمین میکند که خروجی LLM ارزشها و اولویتهای انسانی را منعکس نماید. برخی تحقیقات اولیه وجود دارد که نشان میدهد این مرحله برای رسیدن یا پیشی گرفتن از عملکرد در سطح انسانی حیاتی است. در واقع، ترکیب یادگیری تقویتی (reinforcement learning) و مدلسازی زبان امیدوارکننده است و احتمالاً منجر به پیشرفتهای گستردهای نسبت به LLMهایی که در حال حاضر داریم، میشود.
اکنون بیایید درک خود را درباره برخی نکات مربوط به مدل های زبانی بزرگ که تا اینجا فراگرفتیم، بیازماییم.
اول اینکه چرا یک LLM می تواند یک متن طولانی را خلاصه کند؟
(واقعا کار جالبی است، کافی است یک سند را به آن بدهید و بخواهید آن را خلاصه کند). پاسخ این سؤال، در داده های آموزشی نهفته است. متون خلاصهشده توسط انسانها را به وفور میتوان در اینترنت، مقالات پژوهشی و کتابها پیدا کرد. در نتیجه، یک LLM که با این دادهها آموزش دیده، یاد میگیرد که چگونه این کار را انجام دهد؛ یعنی یاد میگیرد نکات اصلی را استخراج کرده و آنها را در یک متن کوتاه فشرده کند.
در واقع وقتی خلاصهای تولید میشود، متن کامل بخشی از ورودی LLM بوده است. این امر شبیه یک مقاله تحقیقاتی است که یک نتیجه گیری کوتاه دارد، در حالی که متن کامل درست قبل از آن ارائه شده است. در نتیجه، احتمالاً این مهارت در طول پیشآموزش آموخته شده، اگرچه مطمئناً تنظیم دقیق دستورالعمل به بهبود بیشتر آن کمک کرده است.
دوم، چرا یک LLM میتواند به سوالات مربوط به دانش روز پاسخ دهد؟
همانطور که گفته شد، توانایی عمل به عنوان یک دستیار و پاسخدهی مناسب به سوالات، به دلیل تنظیم دقیق دستورالعمل و RLHF است؛ اما تمام (یا بیشتر) دانش لازم برای پاسخ به سؤالات در طول پیشآموزش به دست میآید. البته، این امر یک سوال بزرگ دیگر را ایجاد میکند: اگر LLM جواب را نداند چه؟ متأسفانه، در آن صورت ممکن است یک پاسخ بیاساس بسازد. برای درک دلیل این امر، باید دوباره به دادههای آموزشی و هدف آموزش برگردیم.
ممکن است اصطلاح «توهم» (hallucination) در حوزه مدلهای زبانی بزرگ را شنیده باشید. این اصطلاح به پدیدهای اشاره دارد که طی آن LLMها خودشان حقایقی را خلق میکنند، در حالیکه نباید چنین کاری کنند. چرا این اتفاق میافتد؟ LLM فقط میآموزد که متن تولید کند، نه اینکه متن واقعی بسازد. هیچ شاخص صدق یا اطمینانی در آموزش وجود ندارد که LLM از آن استفاده کند. به طور کلی متن موجود در اینترنت و در کتابها مطمئن به نظر میرسد، بنابراین LLM یاد میگیرد که متنی تولید کند که مانند آن دادهها به نظر برسد، حتی اگر اشتباه باشد.
همانطور که گفته شد، این بحث، یک حوزه تحقیقاتی فعال است و میتوان انتظار داشت که LLM ها به مرور، کمتر مستعد توهم باشند. به عنوان مثال، در طول تنظیم دستورالعمل میتوانیم به LLM آموزش دهیم که تا حدی از توهم پرهیز کند، اما فقط زمان نشان میدهد که آیا میتوانیم این مشکل را به طور کامل حل کنیم یا نه.
ممکن است تعجب کنید که همین جا واقعاً میتوانیم این مشکل را حل کنیم؛ زیرا دانش لازم برای یافتن راه حلی نسبی را داریم که امروزه به طور گسترده مورد استفاده قرار میگیرد.
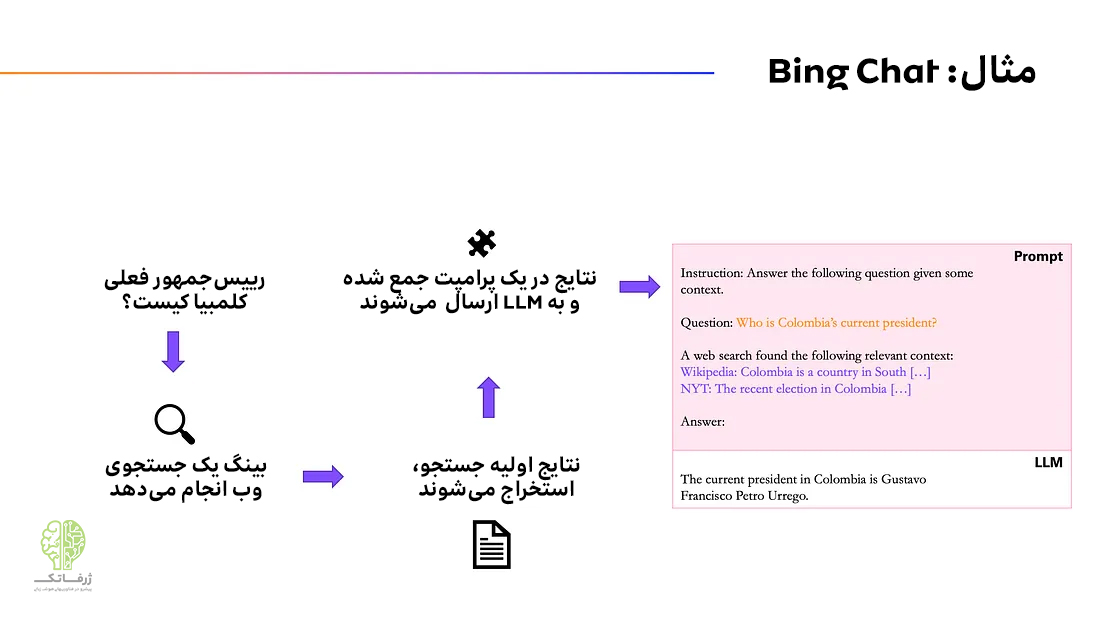
فرض کنید که سؤال زیر از LLM را بپرسید:
رئیس جمهور فعلی کلمبیا کیست؟
این احتمال وجود دارد که یک LLM اشتباه پاسخ دهد؛ به دو دلیل:
اول به دلیلی که قبلاً مطرح کردیم: ممکن است LLM توهم داشته باشد و به سادگی با یک نام اشتباه یا حتی جعلی پاسخ دهد.
دلیل دوم به صورت کوتاه این است: LLMها با دادههای جمعآوریشده تا یک تاریخ خاص آموزش میبینند و این تاریخ مثلا میتواند سال گذشته باشد. به همین دلیل، LLM نمیتواند نام رئیسجمهور فعلی را بداند، زیرا ممکن است از زمان ایجاد دادهها همه چیز تغییر کرده باشد.
چگونه میتوانیم این دو مشکل را حل کنیم؟ پاسخ در ارائه برخی مفاهیم زمینهای مرتبط به LLM نهفته است. منطق این است که هر چیزی که در توالی ورودی LLM وجود دارد به آسانی برای پردازش در دسترس است، در حالی که بازیابی دانش ضمنی که در پیشآموزش به دست آورده، دشوارتر و مخاطرهآمیزتر است.
فرض کنید میخواهیم مقاله ویکیپدیا درباره تاریخ سیاسی کلمبیا را بهعنوان منبعی برای LLM ورودی بدهیم. در این صورت احتمال پاسخ صحیح، بسیار بیشتر است زیرا LLM به سادگی میتواند نام را از متن استخراج کند (با توجه به اینکه به روز است و نام رئیس جمهور فعلی را در بر دارد.). در تصویر بالا میتوانید ببینید که یک پرامپت معمولی برای یک LLM با مفاهیم زمینهای اضافهتر میتواند چگونه باشد. این فرآیند، زمینهسازی برای LLM در زمینه مورد نظر (grounding the LLM in the context) یا دنیای واقعی، نامیده میشود. با این کار به LLM اجازه نمیدهیم آزادانه متن خودش را تولید کند. و این دقیقاً همان کارکرد کوپایلوت و سایر LLM های مبتنی بر جستجو است. آنها ابتدا متن مربوطه را با استفاده از یک موتور جستجو از وب استخراج می کنند و سپس تمام آن اطلاعات را در کنار سؤال اولیه کاربر به LLM ارسال می کنند. برای مشاهده نحوه انجام این کار، به تصویر بالا مراجعه کنید.
اکنون که با مفاهیم اصلی هوش مصنوعی مولد و مدل های زبانی بزرگ آشنا شدیم، آمادهایم تا در قسمت بعدی چند ترفند کاربردی را برای استفاده از آنها معرفی کنیم.